昨天我們講了一些歷史故事,主要是在介紹CNN界的兩位始祖:LeNet與AlexNet,一來是讓大家知道CNN的歷史比我們想像的還要久,二來也是藉由他們說明主流的CNN架構如何設計。今天我們回到實作的部分,讓大家實際感受一下這兩種模型的運作方式。
昨天只有稍微介紹過LeNet-5的歷史背景,今天我們搭配著程式碼具體的來看一下每個細節!
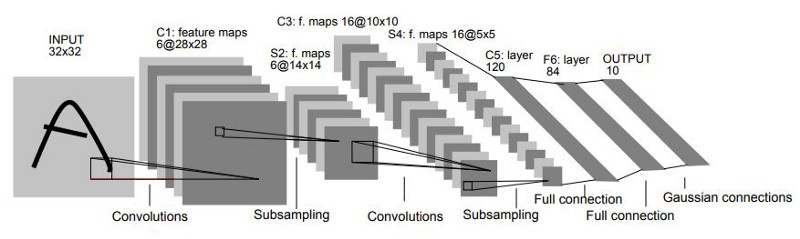
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
# Layer C1: Convolutional layer
self.c1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)
# Layer S2: Sub-sampling layer (Max-Pooling)
self.s2 = nn.MaxPool2d(kernel_size=2, stride=2)
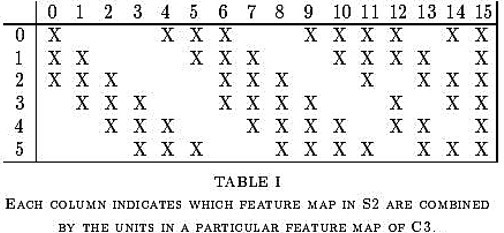
# Layer C3: Convolutional layer with special connections
self.c3_1 = nn.Conv2d(in_channels=3, out_channels=1, kernel_size=5)
self.c3_2 = nn.Conv2d(in_channels=3, out_channels=1, kernel_size=5)
self.c3_3 = nn.Conv2d(in_channels=3, out_channels=1, kernel_size=5)
self.c3_4 = nn.Conv2d(in_channels=3, out_channels=1, kernel_size=5)
self.c3_5 = nn.Conv2d(in_channels=3, out_channels=1, kernel_size=5)
self.c3_6 = nn.Conv2d(in_channels=3, out_channels=1, kernel_size=5)
self.c3_7 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_8 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_9 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_10 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_11 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_12 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_13 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_14 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_15 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_16 = nn.Conv2d(in_channels=6, out_channels=1, kernel_size=5)
# Layer S4: Sub-sampling layer (Max-Pooling)
self.s4 = nn.MaxPool2d(kernel_size=2, stride=2)
# Layer C5: Fully connected layer
self.c5 = nn.Linear(5 * 5 * 16, 120)
# Layer F6: Fully connected layer
self.f6 = nn.Linear(120, 84)
# Output layer
self.output = nn.Linear(84, 10)
def forward(self, x):
# Layer C1: Convolutional layer
x = torch.relu(self.c1(x))
# Layer S2: Sub-sampling layer
x = self.s2(x)
# Layer C3: Convolutional layer with special connections
x1 = torch.relu(self.c3_1(x[:,:3,:,:]))
x2 = torch.relu(self.c3_2(x[:,1:4,:,:]))
x3 = torch.relu(self.c3_3(x[:,2:5,:,:]))
x4 = torch.relu(self.c3_4(x[:,3:6,:,:]))
x5 = torch.relu(self.c3_5(torch.cat((x[:,:1,:,:], x[:,4:6,:,:]), dim=1)))
x6 = torch.relu(self.c3_6(torch.cat((x[:,:2,:,:], x[:,5:6,:,:]), dim=1)))
x7 = torch.relu(self.c3_7(x[:,0:4,:,:]))
x8 = torch.relu(self.c3_8(x[:,1:5,:,:]))
x9 = torch.relu(self.c3_9(x[:,2:6,:,:]))
x10 = torch.relu(self.c3_10(torch.cat((x[:,:1,:,:], x[:,3:6,:,:]), dim=1)))
x11 = torch.relu(self.c3_11(torch.cat((x[:,:2,:,:], x[:,4:6,:,:]), dim=1)))
x12 = torch.relu(self.c3_12(torch.cat((x[:,:3,:,:], x[:,5:6,:,:]), dim=1)))
x13 = torch.relu(self.c3_13(torch.cat((x[:,:2,:,:], x[:,3:5,:,:]), dim=1)))
x14 = torch.relu(self.c3_14(torch.cat((x[:,1:3,:,:], x[:,4:6,:,:]), dim=1)))
x15 = torch.relu(self.c3_15(torch.cat((x[:,:1,:,:], x[:,2:4,:,:], x[:,5:6,:,:]), dim=1)))
x16 = torch.relu(self.c3_16(x))
x = torch.cat((x1, x2, x3, x4, x5, x6, x7, x8, x9, x10, x11, x12, x13, x14, x15, x16), dim=1)
# Layer S4: Sub-sampling layer
x = self.s4(x)
# Flatten the feature maps for fully connected layers
x = x.view(x.size(0), -1)
# Layer C5: Fully connected layer
x = torch.relu(self.c5(x))
# Layer F6: Fully connected layer
x = torch.relu(self.f6(x))
# Output layer
x = self.output(x)
return x
(5*5*3+1)*6+(5*5*4+1)*9+(5*5*6+1)*1=1516
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
batch_size = 64
learning_rate = 0.001
num_epochs = 10
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
model = LeNet5()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward pass and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{total_step}], Loss: {loss.item():.4f}')
print('Training finished.')
model.eval(),後者指的是with torch.no_grad():,目的在於告訴模型說現在我們只是在測試模型,不需要訓練,所以不用計算梯度,也不需要更新參數。這樣的另外一個好處是因為少了很多步驟,所以可以讓整個流程變快一點。model.eval() # Set model to evaluation mode
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Test Accuracy: {100 * correct / total}%')
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
# Layer C1: Convolutional layer
self.c1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)
# Layer S2: Sub-sampling layer (Max-Pooling)
self.s2 = nn.MaxPool2d(kernel_size=2, stride=2)
# Layer C3: Convolutional layer with special connections
self.c3_1 = nn.Conv2d(in_channels=3, out_channels=1, kernel_size=5)
self.c3_2 = nn.Conv2d(in_channels=3, out_channels=1, kernel_size=5)
self.c3_3 = nn.Conv2d(in_channels=3, out_channels=1, kernel_size=5)
self.c3_4 = nn.Conv2d(in_channels=3, out_channels=1, kernel_size=5)
self.c3_5 = nn.Conv2d(in_channels=3, out_channels=1, kernel_size=5)
self.c3_6 = nn.Conv2d(in_channels=3, out_channels=1, kernel_size=5)
self.c3_7 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_8 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_9 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_10 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_11 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_12 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_13 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_14 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_15 = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=5)
self.c3_16 = nn.Conv2d(in_channels=6, out_channels=1, kernel_size=5)
# Layer S4: Sub-sampling layer (Max-Pooling)
self.s4 = nn.MaxPool2d(kernel_size=2, stride=2)
# Layer C5: Fully connected layer
self.c5 = nn.Linear(5 * 5 * 16, 120)
# Layer F6: Fully connected layer
self.f6 = nn.Linear(120, 84)
# Output layer
self.output = nn.Linear(84, 10)
def forward(self, x):
# Layer C1: Convolutional layer
x = torch.relu(self.c1(x))
# Layer S2: Sub-sampling layer
x = self.s2(x)
# Layer C3: Convolutional layer with special connections
x1 = torch.relu(self.c3_1(x[:,:3,:,:]))
x2 = torch.relu(self.c3_2(x[:,1:4,:,:]))
x3 = torch.relu(self.c3_3(x[:,2:5,:,:]))
x4 = torch.relu(self.c3_4(x[:,3:6,:,:]))
x5 = torch.relu(self.c3_5(torch.cat((x[:,:1,:,:], x[:,4:6,:,:]), dim=1)))
x6 = torch.relu(self.c3_6(torch.cat((x[:,:2,:,:], x[:,5:6,:,:]), dim=1)))
x7 = torch.relu(self.c3_7(x[:,0:4,:,:]))
x8 = torch.relu(self.c3_8(x[:,1:5,:,:]))
x9 = torch.relu(self.c3_9(x[:,2:6,:,:]))
x10 = torch.relu(self.c3_10(torch.cat((x[:,:1,:,:], x[:,3:6,:,:]), dim=1)))
x11 = torch.relu(self.c3_11(torch.cat((x[:,:2,:,:], x[:,4:6,:,:]), dim=1)))
x12 = torch.relu(self.c3_12(torch.cat((x[:,:3,:,:], x[:,5:6,:,:]), dim=1)))
x13 = torch.relu(self.c3_13(torch.cat((x[:,:2,:,:], x[:,3:5,:,:]), dim=1)))
x14 = torch.relu(self.c3_14(torch.cat((x[:,1:3,:,:], x[:,4:6,:,:]), dim=1)))
x15 = torch.relu(self.c3_15(torch.cat((x[:,:1,:,:], x[:,2:4,:,:], x[:,5:6,:,:]), dim=1)))
x16 = torch.relu(self.c3_16(x))
x = torch.cat((x1, x2, x3, x4, x5, x6, x7, x8, x9, x10, x11, x12, x13, x14, x15, x16), dim=1)
# Layer S4: Sub-sampling layer
x = self.s4(x)
# Flatten the feature maps for fully connected layers
x = x.view(x.size(0), -1)
# Layer C5: Fully connected layer
x = torch.relu(self.c5(x))
# Layer F6: Fully connected layer
x = torch.relu(self.f6(x))
# Output layer
x = self.output(x)
return x
batch_size = 64
learning_rate = 0.001
num_epochs = 10
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
model = LeNet5()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward pass and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{total_step}], Loss: {loss.item():.4f}')
print('Training finished.')
model.eval() # Set model to evaluation mode
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Test Accuracy: {100 * correct / total}%')
# Define the AlexNet model
class AlexNet(nn.Module):
def __init__(self, num_classes=10):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# Define the AlexNet model
class AlexNet(nn.Module):
def __init__(self, num_classes=10):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
# Hyperparameters
batch_size = 64
learning_rate = 0.001
num_epochs = 10
# Data preprocessing and loading
transform = transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, transform=transform)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Initialize the AlexNet model
model = AlexNet(num_classes=10).to(device)
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Training loop
total_step = len(train_loader)
for epoch in range(num_epochs):
model.train()
for i, (images, labels) in enumerate(train_loader):
outputs = model(images.to(device))
loss = criterion(outputs, labels.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{total_step}], Loss: {loss.item():.4f}')
# Evaluation
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Test Accuracy: {100 * correct / total}%')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")這個東西,讓我們在硬體設備中有支援的GPU存在時可以使用GPU加速,這也是AlexNet與LeNet-5最大的不同:使用GPU加速訓練。

 iThome鐵人賽
iThome鐵人賽